On the Information Theory of Deep Neural Networks
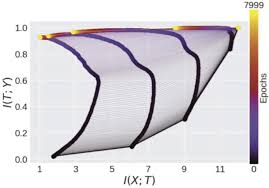 Image credit: Unsplash
Image credit: UnsplashAbstract
Despite numerous breakthroughs, Deep Neural Networks (DNNS) are often treated as black boxes owing to our poor understanding of their internal organization and optimization process. We address this limitation by suggesting that DNNS learn to optimize the mutual information that each layer preserves on the input and output variables, resulting from tradeoff in compression and prediction per each layer. In this talk, we will present analytical and numerical study of DNNS in the Information Plane, and how the Stochastic Gradient Decent (SGD) algorithm follows the information bottleneck trade-off principle. We show how SGD achieves this optimal bound, as the compression for each layer amounts to relaxation to a maximum conditional entropy state subject to the proper constraints on the error and information of the labels. Thus, our works suggests that DNNs are essentially a technique for solving the information bottleneck problem for large scale learning tasks.