Representation Compression in Deep Neural Network
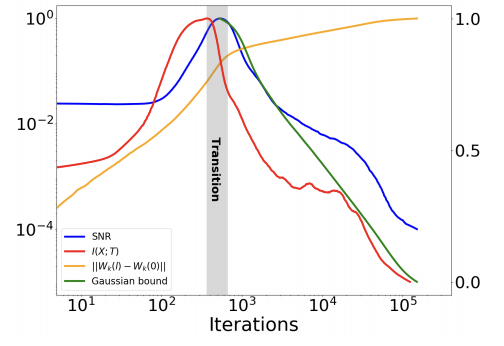 Image credit: Unsplash
Image credit: UnsplashAbstract
Understanding the groundbreaking performance of Deep Neural Networks is one of the greatest challenges to the scientific community today. In this work, we introduce an information theoretic viewpoint on the behavior of deep networks optimization processes and their generalization abilities. By studying the Information Plane, the plane of the mutual information between the input variable and the desired label, for each hidden layer. Specifically, we show that the training of the network is characterized by a rapid increase in the mutual information (MI) between the layers and the target label, followed by a longer decrease in the MI between the layers and the input variable. Further, we explicitly show that these two fundamental information-theoretic quantities correspond to the generalization error of the network, as a result of introducing a new generalization bound that is exponential in the representation compression. The analysis focuses on typical patterns of large-scale problems. For this purpose, we introduce a novel analytic bound on the mutual information between consecutive layers in the network. An important consequence of our analysis is a super-linear boost in training time with the number of non-degenerate hidden layers, demonstrating the computational benefit of the hidden layers.